CUDA C Program structure
CUDA C program structure
Execution of a CUDA program
The Structure of a CUDA C program reflects the coexistence of a host (CPU) and one or more devices (GPU) in the computer. CUDA C source file can have a mixture of host code and device code. By default, any traditional C program is a CUDA program that contains only host code.
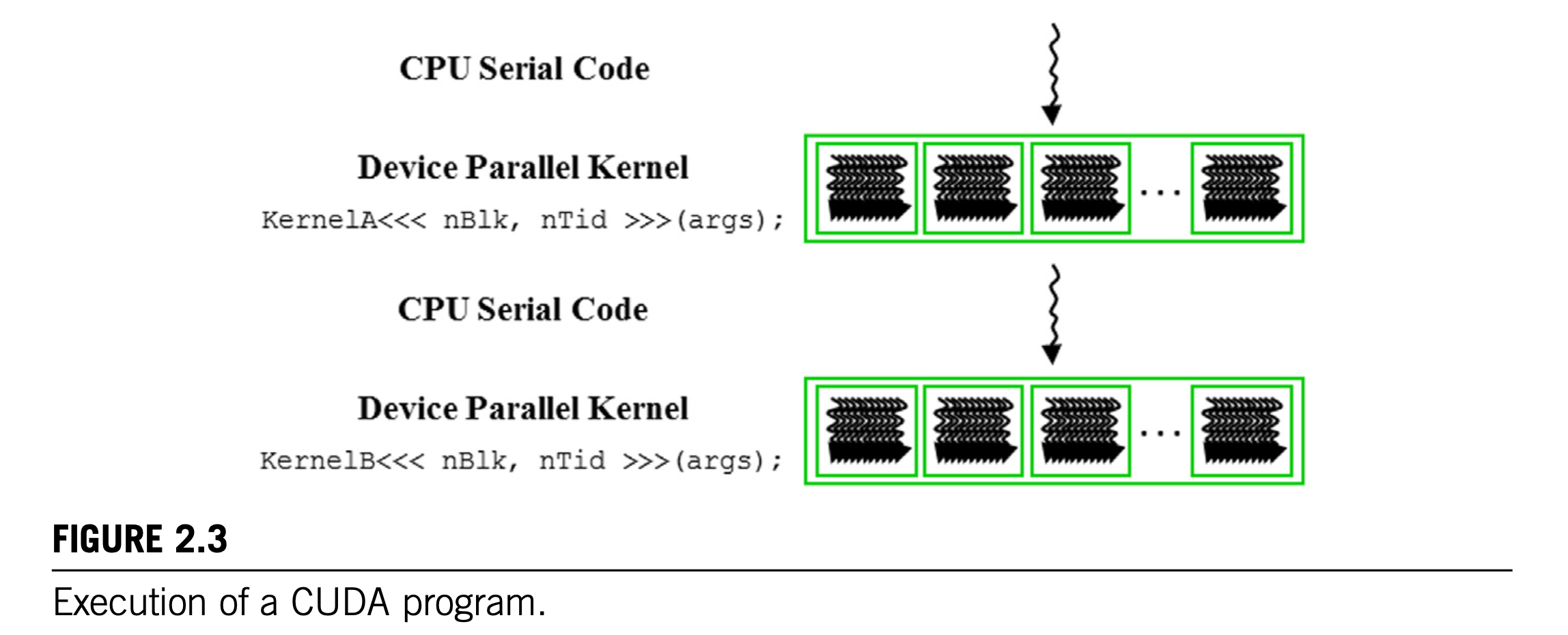 host code和device code按图中顺序交替执行。
host code和device code按图中顺序交替执行。
CUDA thread
- In CUDA, the execution of each thread is sequential.
- CUDA program initiates parallel execution by calling kernel functions, which causes the underlying runtime mechanisms to launch a grid of threads that process different parts of the data in parallel.
- CUDA programmer can assume that GPU threads take very few clock cycles to generate and schedule, owing to efficient hardware support. This assumption contrasts with traditional CPU threads, which typically take thousands of clock cycles to generate and schedule. "CUDA thread overhead is much less than CPU thread".
CUDA vector addition example
sequential process
// compute vector sum C_h = A_h + B_h
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
for (int i = 0; i < n; ++i) {
C_h[i] = A_h[i] + B_h[i];
}
}
int main() {
// Memory allocation for arrays A, B, C
// I/O to read A and B, N elements each to initialize them.
...
vecAdd(A, B, C, N);
}
"_h" for "used for host" and "_d" for "used for device"
parallel process
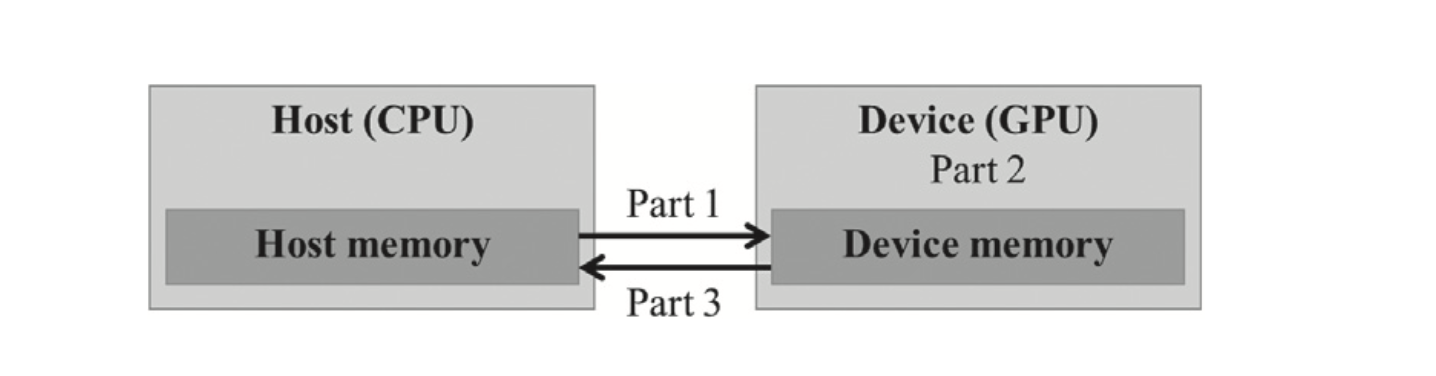
- part 1:
- function allocates space in device(GPU) memory to hold copies of the A, B, C vectors
- copies the A and B vectors from the host memory to the device memory
- needs CUDA API functions to:
- allocate device global memory for A, B, C
cudaMalloc() - transfer A and B from host to device
- allocate device global memory for A, B, C
- part2:
- calls the actual vector addition kernel to launch a grid of threads on the device
- part3:
- copies the sum vector C from the device memory to the host memory
- deallocates the A, B, C array from the device memory
- needs CUDA API functions to:
- transfer C from device to host after vector addition
- free the device global memory for A, B, C
cudaFree()
void vecAdd(float* A, float* B, float* C, int n) {
int size = n * sizeof(float);
float *d_A *d_B *d_C;
// Part 1: Allocate device memory for A, B, and C
// Copy A and B to device memory
...
// Part 2: Call kernel - to launch a grid of threads
// to perform the actual vector addition
...
// Part 3: Copy C from the device memory
// Free device vectors
...
}
vecAdd function is an outsourcing agent that:
- ships input data to a device
- activates the calculation on the device
- collects the results from the device
Device global memory and data transfer
cudaMalloc and cudaFree
cudaMalloc(void** devPtr, size_t size)
Allocate memory on the device.
- Brief
- Allocates
sizebytes of linear memory on the device and returns in*devPtra pointer to the allocated memory in device global memory, the device global memory address should not be dereferenced in the host code. - The allocated memory is suitably aligned for any kind of variable.
- The memory is not cleared.
- Allocates
- Parameters
devPtrAddress of pointer to allocated device memorySizeRequested allocation size in bytes
- Returns
cudaSuccess,cudaErrorMemoryAllocation
void*is a "pointer to anything",void**is a "pointer to 'pointer to anything'"
cudaFree(void* devPtr)
- Brief
- Frees memory on the device.
- Parameters
devPtrDevice pointer to memory to free
- Returns
cudaSuccess,cudaErrorInvalidValue
example:
float * A_d;
int size = n * sizeof(float)
cudaMalloc((void**)&A_d, size);
...
cudaFree(A_d);
cudaMemCpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
- Brief
- Copies data between host and device
- Parameters
dstDestination memory addresssrcSource memory addresscountSize in bytes to copykindType to transfer
- Returns
cudaSuccess,cudaErrorInvalidValue,cudaErrorInvalidMemcpyDirection
- Description
- Copies
countbytes from the memory area pointed to bysrcto the memory area pointed to bydstwherekindspecifies the direction of the copy, and must be one ofcudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice, orcudaMemCpyDefault. PassingcudaMemcpyDefaultis recommended.
- Copies
cudaMemcpyoperations, issued in the same direction (i.e. host to device) will always serialize. The data will not be “copied in parallel”. This is due to the characteristics of the PCIE bus: only one outstanding operations can be transmitted at a time.
with these CUDA API, we can continue with vecAdd function:
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
int size = n * sizeof(float);
float *A_d, *B_d, *C_d;
// Part 1: Allocate device memory for A, B, and C
cudaMalloc((void**)&A_d, size);
cudaMalloc((void**)&B_d, size);
cudaMalloc((void**)&C_d, size);
// Copy A and B to device memory
cudaMemcpy(A_d, A_h, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B_h, cudaMemcpyHostToDevice);
// Part 2: Call kernel - to launch a grid of threads
// to perform the actual vector addition
...
// Part 3: Copy C from the device memory
cudaMemcpy(C_d, C_h, cudaMemcpyDeviceToHost);
// Free device vectors
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}
Error Checking and Handling in CUDA
// example
cudaError_t error = cudaMalloc((void**)&A_d, size);
if (cudaSuccess != error) {
printf("%s in %s at line %d\n", cudaGetErrorStrig(err), __FILE__, __LINE__);
exit(EXIT_FAILURE);
}
Kernel functions and threading
CUDA C programming is an instance of single-program multiple-data (SPMD) parallel programming style.
CUDA thread hierarchy
When a program's host code calls a kernel, the CUDA runtime system launches a grid of threads that are organized into a two-level hierarchy.
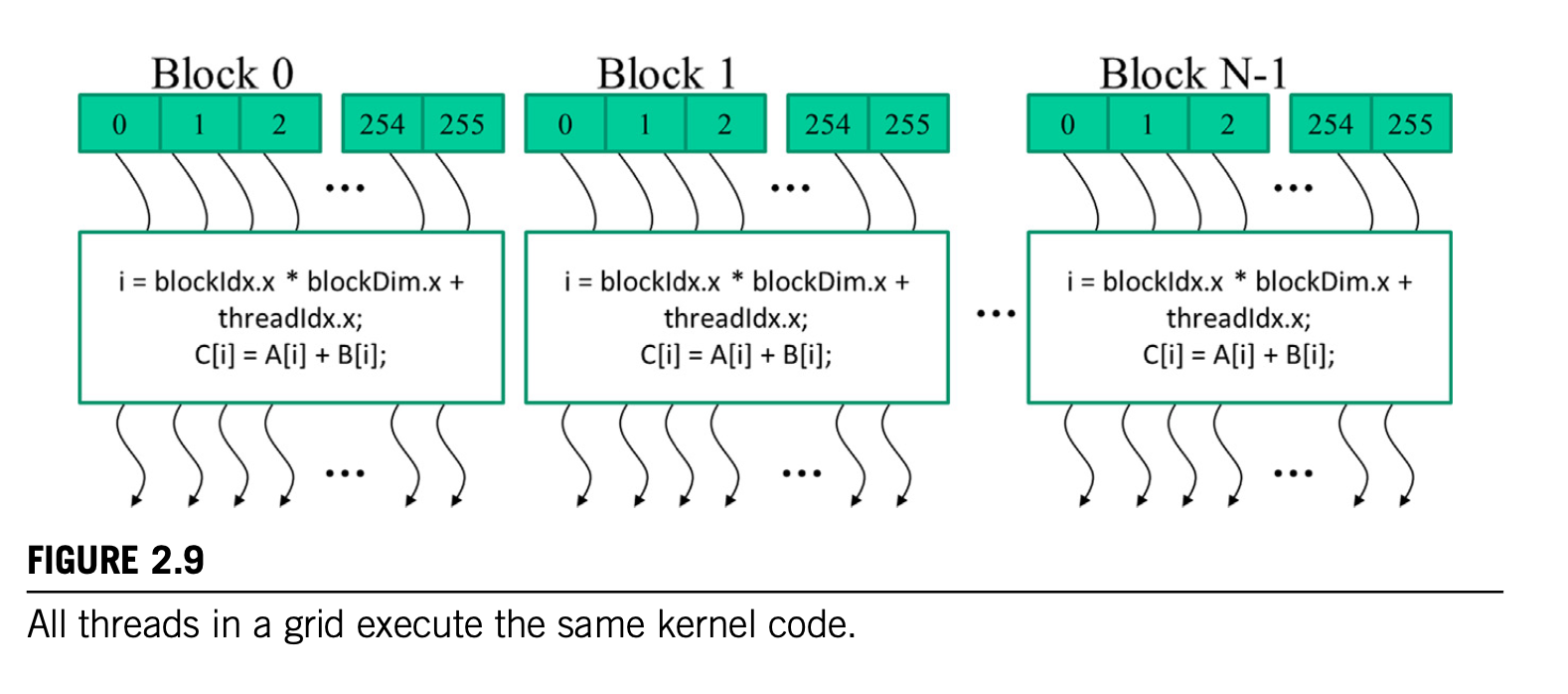
- A grid has N Blocks
- All block of a grid are of same size of threads, its number is
blockDim.
How to distinguish threads from each other?
We need to use two built-in variables: blockIdx and threadIdx
blockIdxvariable gives all threads in a block a common block coordinate.- Threads in the same block distinguish each other with
threadIdx. - The unique index
iis calculated asi = blockIdx.x * blockDim.x + threadIdx.x
CUDA-C function qualifier
By default, all functions in a CUDA program are host functions, which is simply a tradition C function that executes on CPU.
| Qualifier Keyword | Callable From | Executed On | Executed By |
|---|---|---|---|
__host__ default |
Host | Host | Caller Host thread |
__global__ |
Host(or device) | Device | New grid of device threads |
__device__ |
Device | Device | Caller device thread |
CUDA-C built-in variables
threadIdxblockIdxblockDimThese built-in variables are the means for the threads to access hardware registers that provide the identifying coordinates to threads. Different threads will see different values in theirthreadIdx.x,blockIdx.x, andblockDim.xvariables.
Compare C function and kernel function
// C version
void vecAdd(float* A_h, float* B_h, float* C_h, int n) {
for (int i = 0; i < n; ++i) {
C_h[i] = A_h[i] + B_h[i];
}
}
// cuda version
__global__
void vecAddKernel(float* A, float* B, float* C, int n) {
int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i < n) {
C[i] = A[i] + B[i];
}
}
The kernel function does not have a loop that corresponds to on in host version, because the loop is now replaced with grid of threads. The entire grid forms the equivalent of the loop. Each thread in the grid corresponds to one iteration of the original loop.
The
if(i<n)statement allows the kernel to be called to process vectors of arbitrary lengths. For , the code won't run.
Calling kernel function
When the host code calls a kernel, it sets the grid and thread block dimensions via execution configuration parameters.
/**
*@brief vecAdd host code, calls kernel function
*@param [in] A input vector A in host memory, alloc outside vecAdd
*@param [in] B input vector B in host memory, alloc outside vecAdd
*@param [out] C input vector C in host memory, alloc outside vecAdd
*@param [in] n vector length of A, B, and C
*/
void vecAdd(float* A, float* B, float* C, int n) {
float* A_d;
float* B_d;
float* C_d;
int size = n * sizeof(float);
cudaMalloc((void**)&A_d, size);
cudaMalloc((void**)&B_d, size);
cudaMalloc((void**)&C_d, size);
cudaMemcpy(A_d, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B, size, cudaMemcpyHostToDevice);
vecAddKernel<<<ceil(n/256.0), 256>>>(A_d, B_d, C_d, n);
cudaMemcpy(C, C_d, size, cudaMemcpyDeviceToHost);
cudaFree(A_d);
cudaFree(B_d);
cudaFree(C_d);
}
execution configuration parameters is wrapped with <<< and >>> before the traditional C function arguments.
The first configuration parameter gives the number of blocks in the grid.
The second specifies the number of threads in each block.
Compile CUDA-C function

- The host code is compiled with host's standard C/C++ compilers and run as a traditional CPU process.
- The device code, which is marked with CUDA keywords that designate CUDA kernels and their associated helper functions and data structures, is compiled by NVCC into virtual binary files called PTX files. These PTX files are further compiled by a runtime component of NVCC into the real object files and executed on a CUDA-capable GPU device.